15 October 2024
We present a system for generating synthetic reasoning data using program synthesis, designed for the infusion of domain-specific reasoning from knowledge graphs into the training data for large language models.
As publicly available data reaches the limits of its potential for LLM training, leading research labs are increasingly embracing synthetic data generation to expand the training data used in frontier models. In particular, the incorporation of high-quality chain-of-thought (CoT) data has been shown to increase the performance of language models on reasoning benchmarks. However, there is a severe shortage of high-quality CoT reasoning examples available on the public internet, and generating these traces using human annotation is expensive and time-consuming at the scales needed for the next generation of large language models.
Recently, synthetic data pipelines have shown significant promise in expanding the volume of instruction tuning data available for training. The most common approach is to use larger, powerful models to produce instruction examples, which are then used to train smaller, more efficient models. When combined with reward models, human preference feedback, and filtering, this approach can effectively generate the billions of additional tokens necessary for training new generations of models.
However, when applying synthetic generation models to the task of producing longer, more complex reasoning chains—it becomes difficult to verify the integrity of the language model’s output. It is critical to ensure that individual steps in the reasoning chain (a) follow from their previous steps, (b) do not introduce logical reasoning errors, and (c) avoid confabulations.
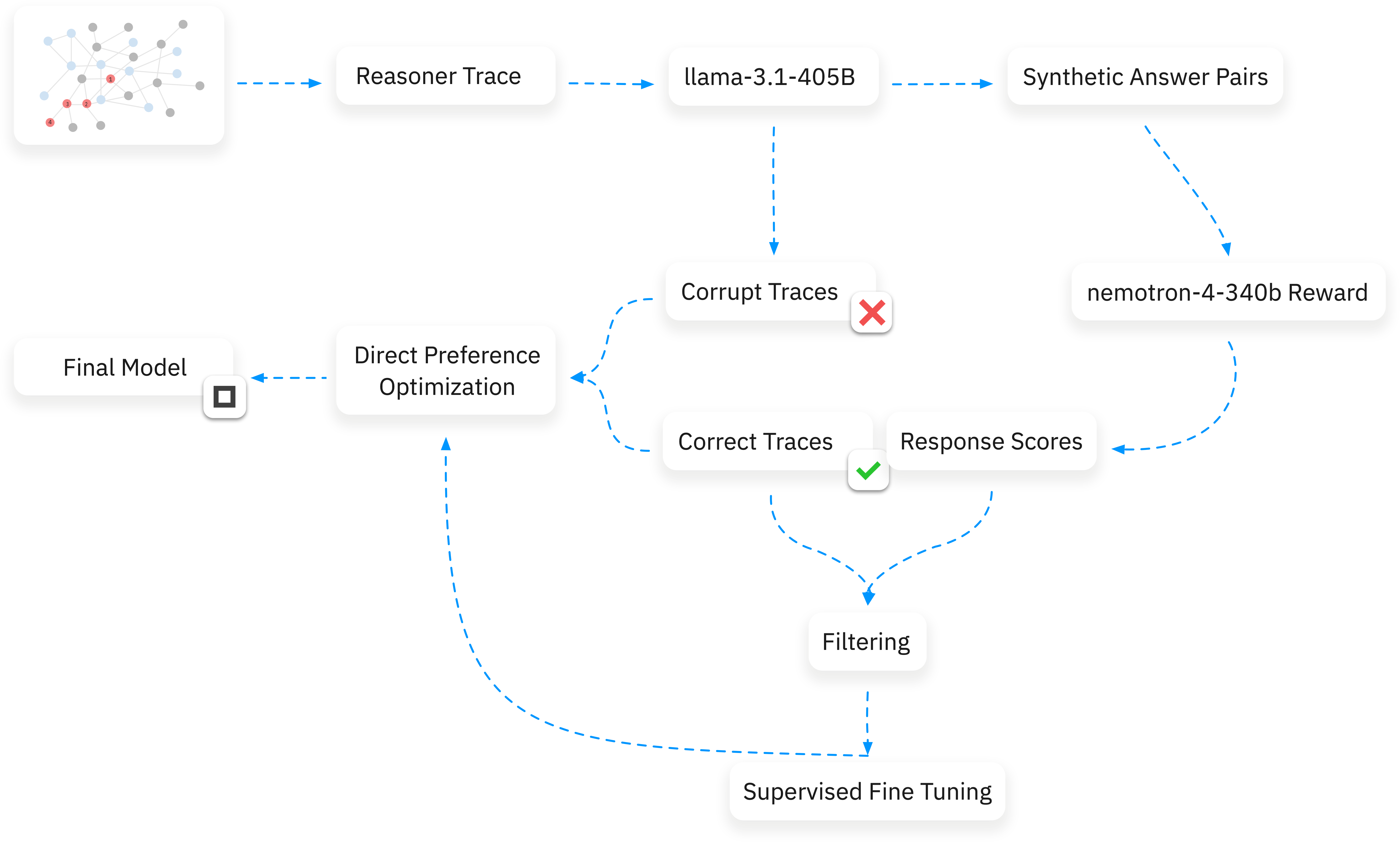
The amount of publicly available and verifiable reasoning traces is remarkably small (often no more than a few thousand examples), and generating such reasoning traces remains a significant cost and challenge. To address this issue, we built Enki, a new approach that generates high-quality reasoning training data from authoritative data sources in large quantities, and with minimal human input. Our method combines knowledge graphs, logic programming, and program synthesis to create synthetic forward reasoning trace data that can be used to train models.
Our search technique uses knowledge graph traversal to extract knowledge embedded in the graph and transform paths in the graph into verifiable chains of deductive reasoning. Walks through the relationships and entities within the graph allow us to programmatically generate arbitrarily complex multi-hop queries that express domain knowledge. These queries are then processed through a back-chaining logic engine to generate detailed, step-by-step reasoning traces. Finally, a small language model verbalizes these traces to produce high-quality CoT reasoning examples, which can be introduced into the instruction tuning pipeline for training.
In addition to instruction tuning, we can also train a process reward models to guide the iterative generation of reasoning traces. From correct answers derived from ground truth we can also produce corrupted reasoning traces which diverge from the correct reasoning trace by randomly deleting or permuting entities and relations. This has the result of essentially introducing non-sequiturs into the reasoning chain.
At each point where we perform a corruption we mark the individual verbalization of that step with bitmask to indicate divergent reasoning steps. When these corrupted traces are introduced into the logic engine they will either fully or partially corrupt the final answer resulting in an incorrect outcome. These negative examples can used for both DPO training and to train the process reward model.

In order to evaluate our system we train a synthetic data generation engine over the Harvard PrimeKG Knowledge Graph, which is a large knowledge graph that contains several million triples concerning medication, diseases, genetics, protein interactions and pathways. It serves as a high quality benchmark for answering complex queries over technical knowledge.
The PrimeKG graph (G) contains several node types representing various pharmacological and biological entities, such as drugs, diseases, genes, and proteins:
diseaseexposurecellular componentdrugpathwaybiological processanatomymolecular functiongene/proteineffect/phenotypeIn addition it has 18 relation types which are typed mapping between various entities:
ppicarrierenzymetransportercontraindicationindicationoff-label usesynergistic interactionassociated withparent-childphenotype absentphenotype presentinteracts withlinked toexpression presentexpression absentside effecttargetTo establish a baseline for performance on complex multi-hop questions over G,
we tested two state-of-the-art large language models: gpt-4o and
claude-3.5-sonnet. These models were evaluated on a set of 517 randomly
generated open-ended questions that require technical biochemistry knowledge in
order to answer. The ground truth to these questions are generated by traversing
the G and extracting golden answer sets and comparing against the model's
output.
We compare this against several variations of the llama 3.1 and 3.2 models which have been trained on synthetic reasoning data.
In order to generate synthetic reasoning traces we use a set of combinators to inductively build up query expressions from simple building blocks. These consist of four combinators which fuse together to form composite queries:

Projection queries (p)
These queries find entities directly connected to a starting entity by a certain relation.
What movies are directed by Quentin Tarantino
?x. ∃y. p(x, "directed by", "Quentin Tarantino")
Intersection queries (i)
These queries identify entities that satisfy multiple conditions simultaneously.
What actors who in movies directed by Quentin Tarantino?
?x. ∃ x y.
i(
p(x, "starred in", y),
p(y, "directed by", "Quentin Tarantino")
)
Union queries (u)
These combine the results of multiple queries.
What movies are directed by Quentin Tarantino or star John Travolta?
?x. ∃ x y.
u(
p(x, "directed by", "Quentin Tarantino"),
p(x, "starred in", "John Travolta")
)
The state space (S) of all permutations of queries over the PrimeKG graph with (4 combinators, 11 ground term types, and 18 relation types) is both vast and sparse. There are many syntactically valid graph queries, but only a small subset of this space is both syntactically and semantically meaningful. In order to explore this state space we employ a neural-guided program synthesis approach which inductively composes the above combinators (i, p, u, n) to build random queries. These queries can be compiled into lower level graph queries and executed over the knowledge graph.

In order to constrain the combinatorial explosion of programs we train our model to compute a value function Vπ which is computed by sampling the number of entities returned by executing 100 instantiations of the query (using random entities from ground term types). The expected reward is computed in terms of the number of queries which return between 0 and 10 entities. The upper bound of 10 is empirically chosen to constrain our final reasoning trace output to fit within the llama-3.1 context window of 8192 tokens.
We also negatively reward queries which return more than 50 entities as these are likely to be overly broad (i.e. "Which genes are expressed in the heart?") and semantically useless. We also introduce the following syntactic constraints.
After several epochs of training the model learns to discover queries from the state space which roughly correspond to several well-known classical categories. We illustrate these with common sense example below:
Multi-hop queries:
What is the age of the head of state of the United Kingdom?
?x. ∃ x y.
p(x, "age", p(y, "head of state", "United Kingdom"))
Intersection with multiple conditions:
What is the capital of France and the home of the Eiffel Tower?
?x. ∃ x y.
i(
p(x, "capital of", "France"),
p(x, "location of", "Eiffel Tower")
)
Nested query with union and intersection:
Which actors have starred in movies directed by either Steven Spielberg or Martin Scorsese, and have won an Oscar?
?x. ∃ x y.
(
i(
p(x, "starred in", y),
u(
p(y, "directed by", "Steven Spielberg"),
p(y, "directed by", "Martin Scorsese")
)
),
p(x, "has won", "Oscar")
)
Complex multi-hop query:
Which university did the spouse of the current president of the United States attend?
?x. ∃ x y.
(
p(x, "attended", y),
p(y, "spouse",
p(current president, "United States")
)
)
Which Turing Award winners teach at university where the spouse of a Academy Award winner studied?
?x. ∃ x y.
i(
p(x, "teaches",
p(y, "award won", "Turing Award")
),
p(x, "attended",
p(y, "spouse of",
p(y, "award won", "Academy Award")
)
)
)
Over the PrimeKG relations, the 1p components can then be composed together with union, intersection, and negation operations to form more complex queries. Each of these queries has a verbalization like the following:
Our model discovers new queries by sampling from the state space to produce complex multi-hop queries which when instantiated with ground terms produce long deductive reasoning chains. A simple question might look like:
Which compounds have transporter genes that interact with ATP-binding and have a synergistic interaction with Icosapent?
?X. ∃Y, Z.
i(
p(X, "transporter",
p(Y, "interacts with", "ATP binding")),
p(Z, "synergistic interaction", "Icosapent")
)
This query is answerable derived from three projections across medications, gene and protein interactions from the PrimeKG graph:
Thus the output of our program synthesis model is a set of queries which cover the entire graph and can be instantiated with random ground terms, executed against the graph, fed into the trace generator, and then verbalized by a small language model to produce the final reasoning trace output.
We use standard accuracy, precision, recall and F1 metrics to comapre generated answers against golden answer sets. For the baseline models we run with temperature of 0.7 and top-p of 0.9. The prompt given to the models was:
Respond to the following biochemical question. Respond only with a list of {RETURN_TYPE} that satisfy the question and nothing more.
{QUESTION}
When prompted to answer these kind of questions models will often respond with abstentions of the form.
I apologize, but I don't have enough reliable information to provide a definitive list of compounds that meet those specific criteria.
This is considered a 0 hit for the model as it does not contain the correct answer in the output. The results of our baseline testing are shown below:
| Model | Precision | Recall | F1 | Accuracy |
|---|---|---|---|---|
| gpt-4o | 0.1399 | 0.0883 | 0.1082 | 0.0411 |
| claude-3.5-sonnet | 0.0872 | 0.1207 | 0.1013 | 0.0809 |
| llama-3.1-70B | 0.1049 | 0.0824 | 0.0923 | 0.1200 |
Notably all of the frontier-family models achieve low accuracy on our open-ended question answering benchmarks over PrimeKG. This low performance underscores the challenging nature of multi-hop reasoning tasks over technical domain knowledge that is likely not fully captured in their training data. We also hypothesize that language models are in general architecturally incapable of performing the precise search, join and set theoretic operations required to give complete and total answers to many of these questions.
In addition, some of the models' answers contained "hallucinated" non-existent drugs or completely fabricated genes and pathways that are not present in human physiology. This presents a serious safety concern for the use of these models in research or high-risk applications.
For model training, we evaluated the training on the llama 3.1 8B and 70B models to do instruction tuning for question answering over the output.
Phase 1: Supervised Fine-Tuning
Phase 2: Direct Preference Optimization
We perform supervised fine-tuning on the following base models in order to measure the effectiveness of our synthetic data in improving the model's ability to perform CoT reasoning over PrimeKG graph entities.
We measure the improvement of the F1 score as compared to the baseline model using the OOD test split of the reasoning-biochem dataset. The results are shown below:
| Model | Accuracy | Precision | Recall | F1 | Improvement over Baseline |
|---|---|---|---|---|---|
| gpt-4o | 0.0411 | 0.1399 | 0.0883 | 0.1082 | - |
| claude-3.5-sonnet | 0.0809 | 0.0872 | 0.1207 | 0.1013 | - |
| llama-3.1-70B | 0.1200 | 0.1049 | 0.0824 | 0.0923 | - |
| llama-3.2-3B (SFT) | 0.2331 | 0.2381 | 0.1613 | 0.1923 | (+0.1000) |
| llama-3.1-8B (SFT) | 0.441 | 0.3673 | 0.2637 | 0.3070 | (+0.2147) |
| llama-3.1-8B (SFT + DPO) | 0.489 | 0.4123 | 0.3012 | 0.3490 | (+0.2567) |
| llama-3.1-70B (SFT) |
While we initially focused on biochemistry over PrimeKG, our process should adapt well to other technical domains. We plan to extend our approach to other large graphs such as the full WikiData graph and to include combinators for expressing arithmetic, temporal, spatial, and other logical primitives into the reasoning traces.
The WikiData graph has over 12,000 relation types and as such has a much larger state space to explore than PrimeKG, however being able to automatically create general purpose reasoning traces over a vast set of Wikipedia would be a significant step forward and holds the promise to produce trillions of new tokens over diverse subjects like common sense reasoning, maths, physics, chemistry, biology, law and medicine while being orders of magnitude cheaper than human annotation.
Our flywheel for generating synthetic reasoning data from knowledge graphs has shown promising initial results in enhancing the performance of LLMs. This approach has the potential to significantly improve the quality and performance of LLMs on complex multi-hop reasoning tasks and its use in the data mixture for can improve the reasoning ability of the model over technical domains which are underrepresented in their training data.
If you found this interesting at all, want to chat about the topic, or would like to learn about how we can help you get better results with your training data mixture, drop us a line at founders@extrasensory.ai.